
Všichni už dnes žijeme v digitální době, která s sebou přináší obrovské objemy vytvářených dat, a to nejen v podnikové praxi, ale i v soukromém životě. Díky sociálním sítím, mobilním telefonům, IoT sítím a dalším technologiím můžeme říct, že žijeme v době dat. Velkou výzvou ale zůstává, jak tato data efektivně zpracovávat a využívat. V poslední době nás díky tomu obklopilo „dosti nejasné, ale velké“ téma – BIG DATA (viz. například https://www.mibcon.cz/a/big-data-takovy-it-yetti).
V současnosti není již problém data vytvářet, ani je ukládat. Pro ukládání velkého množství informací se celosvětově využívá například uznávaná no-sql databáze Apache™ Hadoop®. Její výhoda spočívá v distribuovaném ukládání převážně nestrukturovaných informací a v levném provozu, díky čemuž si vysloužila široké využití.
Do oblasti „velkých“ či „širokých“ dat v posledních letech investují i velké technologické firmy – například společnost SAP se pasovala na leadra zpracovávání strukturovaných informací s využitím pokročilého in-memory computingu, uvedením produktu SAP HANA na trh.
Nastává tedy otázka, jak využít dat strukturovaných a nestrukturovaných, resp. kombinací technologií in-memory computingu a Hadoop, v oblasti analýz. SAP HANA disponuje vlastním datovým rozhraním Smart Data Access (SDA) pro vytěžování dat z Hadoop pomocí Apache Hive, který využívá jazyk komunikace podobný standardnímu SQL jazyku. SAP ale přichází i s další možností, v podobě nového produktu SAP HANA Vora, který zahrnuje in-memory engine (nazývaný jako Hadoop In-Memory Query). Tento nástroj využívá konektor do Apache Spark Execution Framework pro poskytování interaktivních analýz nad daty uloženými v databázi Hadoop a současně umožňuje obohacení dat databáze Hadoop o strukturovaná data ze SAP HANA. Tím je umožněno využití analytických open-source klientů pro Hadoop – například nástroje Zeppelin, kromě ostatních standardních analytických nástrojů platformy SAP BusinessObjects využívaných nad SAP HANA.
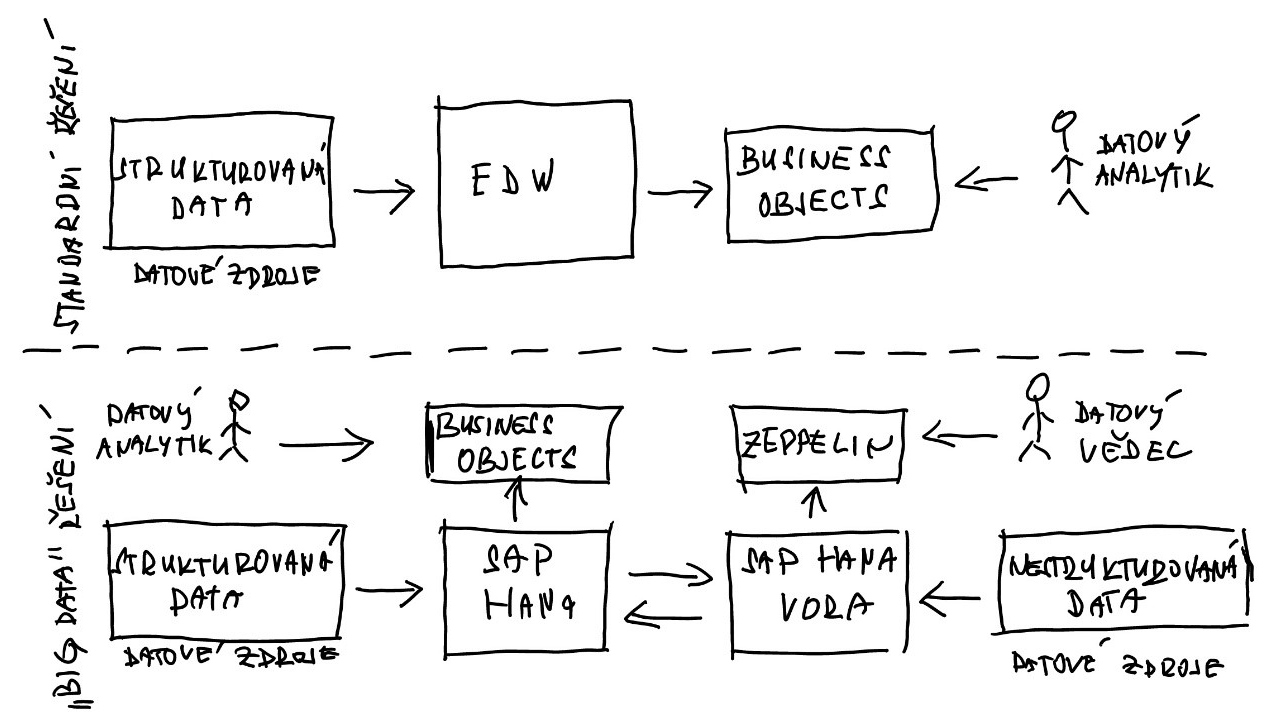
SAP HANA Vora může pracovat jako stand-alone řešení nebo v propojení se SAP HANA Platform. Díky tomu můžeme kombinovat Big Data s korporátními daty jednoduše a rychle.
Přínosy:
- Real-time přístup k Big Data
- Podpora self-service analýz
- Nižší náklady na dostupnost a přístup k archivním datům
Co to umí:
- Možnost vytvářet hierarchie, dril-downs, konverze apod. na Hadoop systémech
- Podporu zpracovávání a kombinace datových subsetů ve Spark a HANA
- Compile queries – vylepšení výkonu běhu dotazů v Spark/Hadoop napříč HDFS nody
- HANA-Spark Adapter – Zvýšení výkonu mezi Spark a HANA
- Jednotné prostředí pro data z Hadoop a HANA
- Open Programming – podpora pro Scala, python, C, C++, R a Java
SAP HANA Vora je řešení postavené na ekosystému Hadoop, což je open-source projekt kombinující několik komponent, které zajišťují distribuované zpracovávání velkých datových množin uložených v clusterové architektuře. Hlavní komponenty použité v této architektuře jsou znázorněny na schématu:
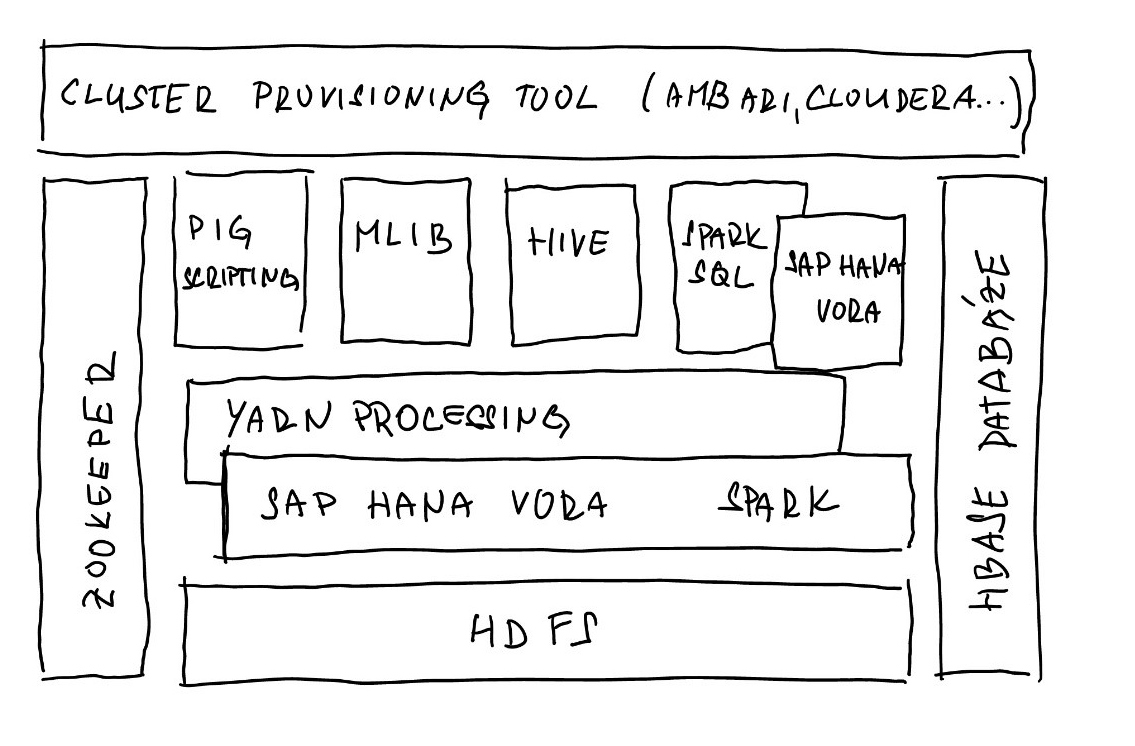
K čemu prakticky SAP HANA Vora využít?
Zjednodušeně řečeno SAP HANA Vora je integrační nástroj mezi SAP HANA a Hadoop a to nám nabízí několik zajímavých možností využití v podnikových procesech.
Jeden příklad ze světa SAP systémů, který se přímo nabízí, je využití Hadoop clusterů pro ukládání „archivních“ dat jak ze systému ERP, tak i dalších datových skladů. Na starší objednávky, faktury, cenové podmínky, data z výrobních linek apod. je potřeba ještě zpětně nahlížet bez možnosti úprav a proto je možné SAP HANA Vora využít v konceptu „multi temperature data“. Tímto konceptem je možné snížit náklady na provoz systémů.
Ačkoliv toto využití je interně přínosné, jsou zde další příklady, neméně zajímavé a čekající na skutečné využití v praxi:
Vyhodnocení dat ze senzorů, kterých bývá obrovské množství - z výrobních linek, elektrického vedení, plynového a vodovodního potrubí, doplněné o údaje z ERP systému, kdy lze následně v reálném čase plánovat údržbu jednotlivých částí sledovaného objektu pro předcházení haváriím a včasnou detekci problematické části.
Velmi rychle se rozvíjející sociální sítě produkují obrovské množství dat a tato data mohou ukazovat na nálady zákazníků. Pro pracovníky call-center může být cennou informací kombinace dat z ERP systémů (např. platební morálka), DW (segmentace, historie nákupů…) a právě dat uložených v Hadoop (např. údaje ze sociálních sítí).
Dalším dynamicky se rozvíjejícím odvětvím je Internet-of-Things (IoT), kde lze tento koncept zpracování dat využít. Při využití dnešních „smart věcí a zařízení“ (veškeré smartphones, smart meters, smart watches, smart vehicles), můžeme získávat nesmírné množství dat a je vhodné je ukládat v neupravené struktuře pro následné vyhodnocení. Lze tedy uvažovat o jejich „business“ využití – například v oblasti dopravy, zdravého života nebo zdravotnictví.
